

Improving Observability of GoLang Services

This blog post is aimed at GoLang developers who are looking to improve the observability of their services. It skips the basics and jumps straight to advanced topics, such as asynchronous structured logging, metrics with exemplars, tracing with TraceQL, aggregating pprof and continuous profiling, microbenchmarks and basic statistics with benchstat, blackbox performance tests, and basic PID controllers for determining a system's maximum load. We'll also briefly touch on current research in the observability space, including active casual profiling and passive critical section detection.
The Three Pillars of Observability: Logs, Metrics, Traces
.png)
If you're reading this, you likely don't need a refresher on the basics of observability. Let's dive into the non-obvious stuff and focus on making it as easy as possible to move between the three main observability surfaces. We'll also discuss how to add tracing to the mix so that pprof data can be linked to tracing and back.
If you're instead looking for a short and straightforward introduction to monitoring basics and ways to quickly introduce basic observability into your service, “Distributed Systems Observability” by Cindy Sridharan is a great place to start.
Structured Logging
Logging can become a bottleneck if you're not using a zero-allocation logging library. If you haven't already, consider using zap or zerolog – both are great choices.
Golang has also an ongoing proposal for introducing structured logging: slog. Be sure to check it out and provide feedback on the proposal!
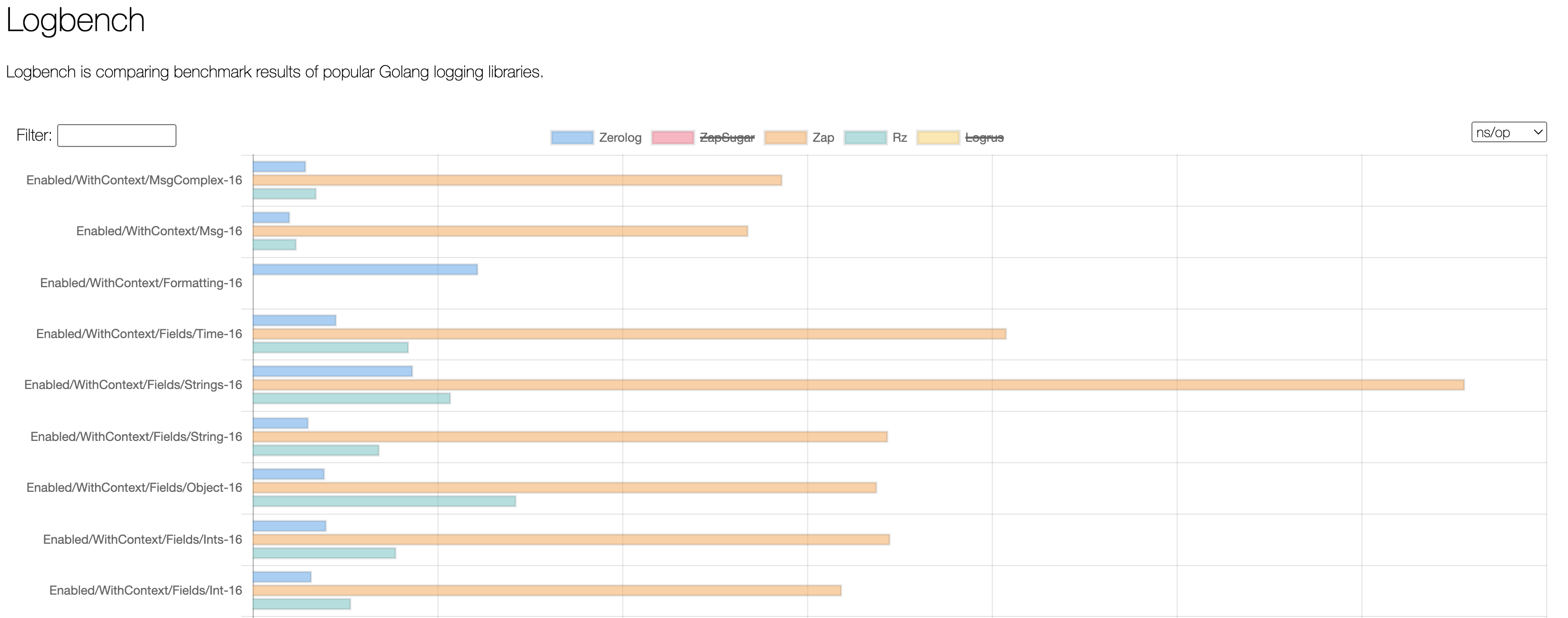
Structured logging is essential for extracting data from logs. Adopting a json or logfmt format simplifies ad-hoc troubleshooting and allows for quick and dirty graphs/alerts while you work on proper metrics. Most log libraries also have ready-to-use hooks for gRPC/HTTP clients and servers, as well as common database clients, which greatly simplifies their introduction into existing codebases.
If you find text-based formats inefficient, you can optimize your logging to a great extent. For instance, zerolog supports binary CBOR format, and Envoy has protobufs for their structured access logs.
In some cases, logs themselves can become performance bottlenecks. You don't want your service to get stuck because Docker can't pull events out of the stderr pipe fast enough when you enable DEBUG logs.
One solution is to sample your logs:
Alternatively, you can make their emission fully asynchronous, so they never block:
One additional note for those of you using Grafana and Loki: you likely want to set up derived fields. This way, you can extract fields from logs and put them into arbitrary URLs.
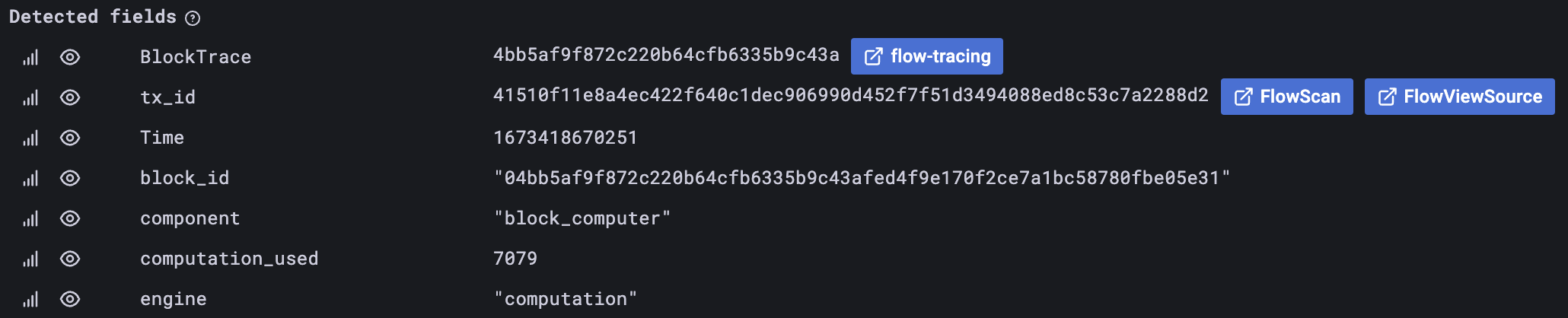
Consider including a trace ID in every log message if the context indicates that tracing should be enabled. You’ll thank yourself later for that.
Metrics
Let's assume you're already using Prometheus-style metrics in your service. But what do you do when you see a spike on your graph and need to figure out what caused the slowdown (spoiler: it's probably the database)? Wouldn't it be great to jump from the metric directly to the trace of the slow request? If so, ExemplarAdder and ExemplarObserver are for you:
Note that you can put not only a trace_id but also arbitrary key-value data into the labels, which is especially useful for multi-tenant environments where you can include user_id or team_id. This can be a cost-effective solution to the high-cardinality metrics problem.
Trace
Tracing is essential for performance analysis in today's world, so most services have it enabled. The industry's journey to tracing has been a bumpy one, from OpenTracing to OpenCensus and now OpenTelemetry. We use a common setup with the OTEL libraries for trace emission and Grafana Tempo as the backend.
Flow's blockchain trace emission is distinct from a typical web backend: we don't rely on the trace context passed between trust boundaries, so instead of propagating TraceIDs, we deterministically construct them based on the object being processed - a hash of a block or transaction hash.
The issue with tracing is not the emission of data, but rather the ability to locate "interesting" data. Default Grafana's search capabilities are quite limited, and it can sometimes take minutes to find the desired trace.
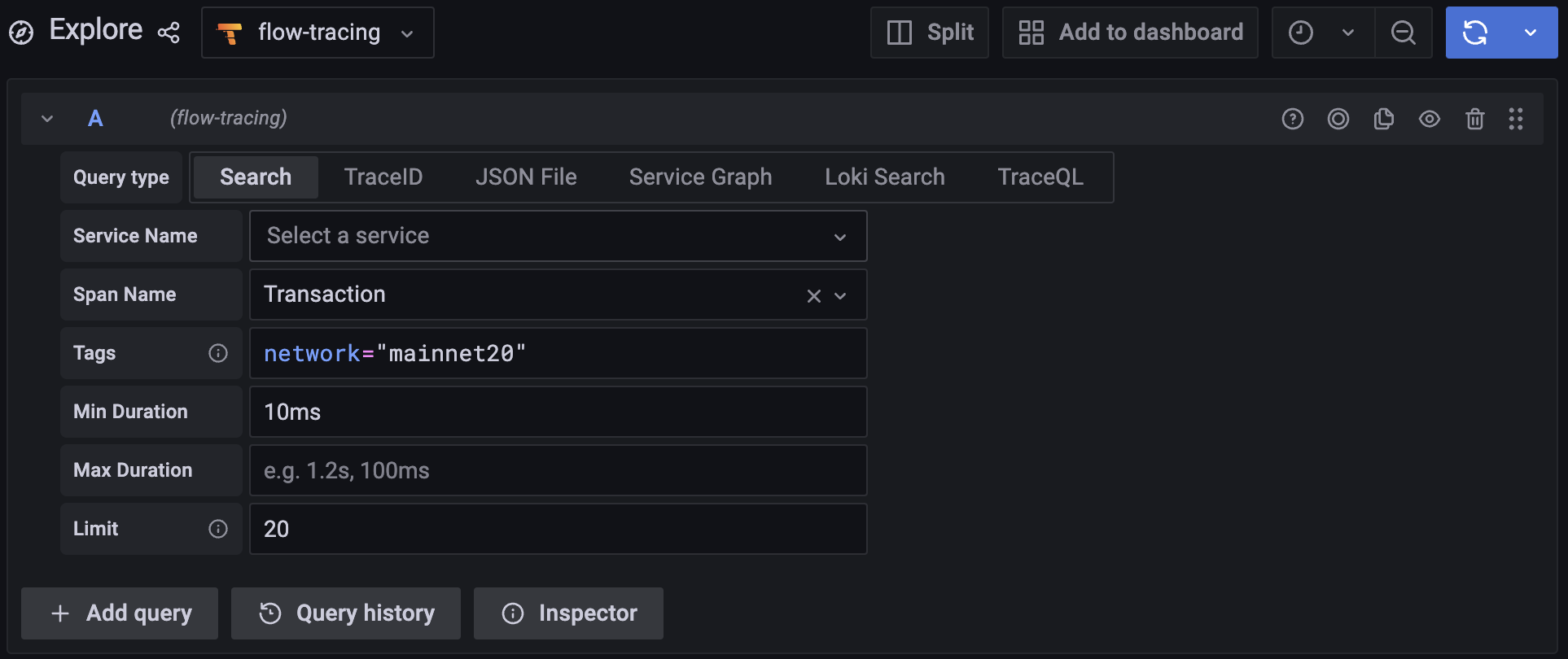
TraceQL solves this issue by introducing a convenient way of searching traces. Finding a specific trace is now a breeze. Here are a few examples from the reference documentation:
If you prefer video format, here is Joe Elliott’s introduction to TraceQL from GrafanaCon 2022.
Now, with TraceQL, we can be as specific as we desire:
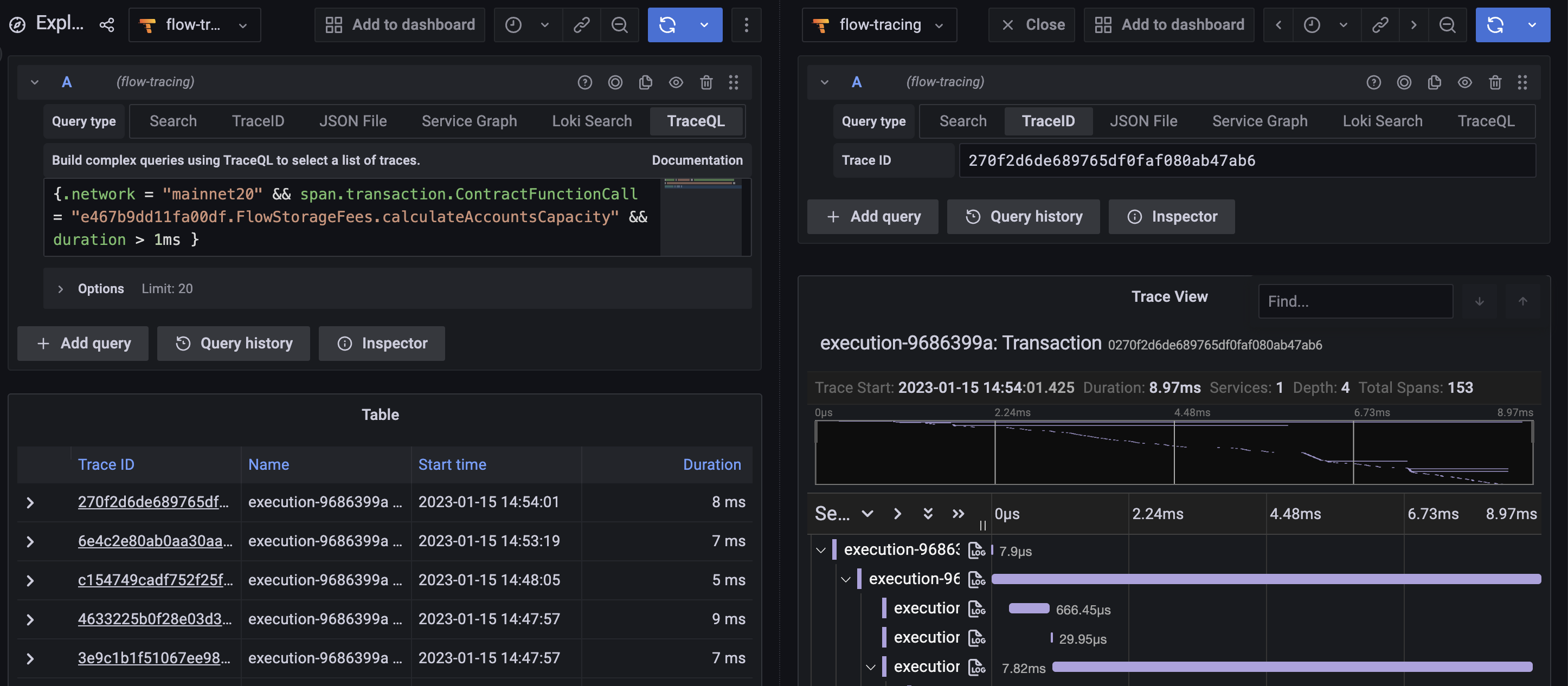
If you're using the Grafana, don't forget to link your log data source to your traces. This will make it easy to navigate between traces and logs:
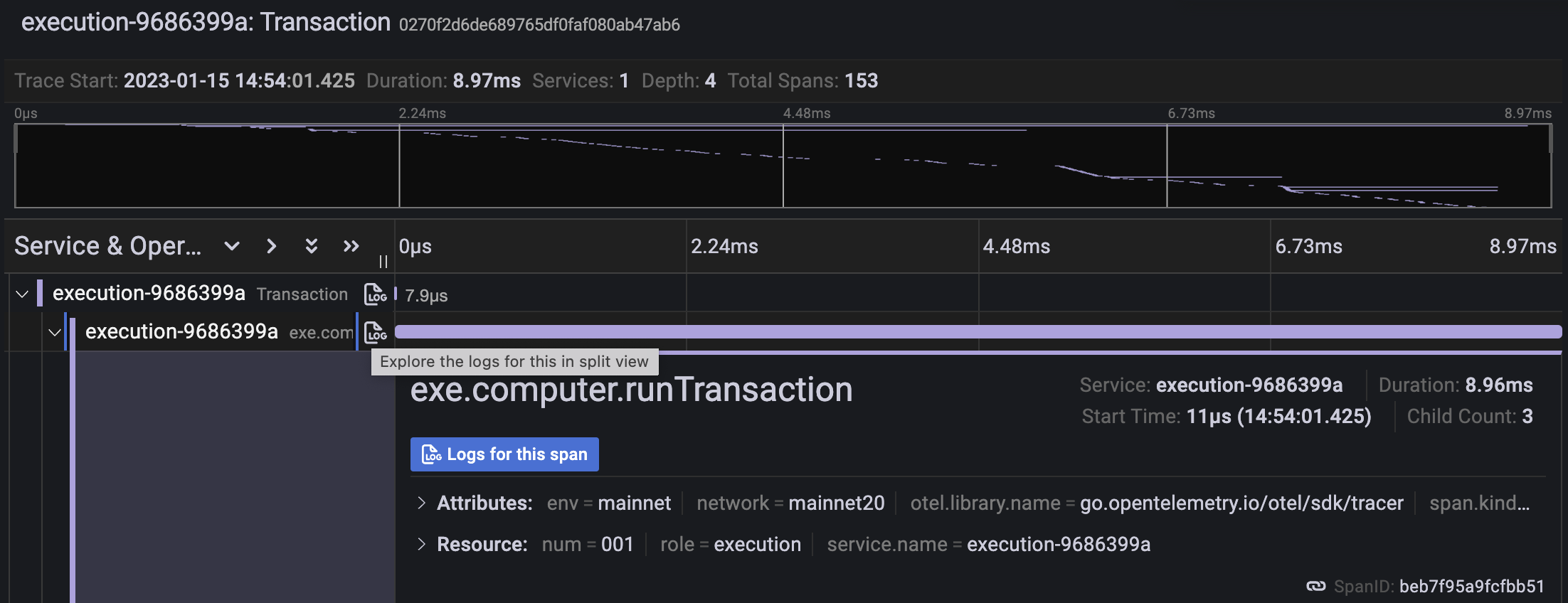
Optimizing TraceQL queries can be achieved by having common per-process attributes in your "resources". This is much faster than searching and can make a huge difference. For example, in the screenshot above we have a bug where env and network should have been emitted as resources instead of attributes.
Profiling
The Go runtime offers excellent profiling capabilities. If you want to instrument your code beyond net/http/pprof, we highly recommend reading DataDog’s “The Busy Developer's Guide to Go Profiling, Tracing and Observability”. It goes into detail into all profiler types (CPU, Memory, Block, etc.) and covers low-level implementation details such as stack trace internals and pprof format.
Many of the profiling features require a new Go runtime for quick and accurate operation. If you intend to rely on profiling data in production, especially if you plan to use continuous profiling, please upgrade to Go 1.19.
Once you have the raw pprof file, you'll want to analyze it. However, go tool pprof -http 5000 has its limits. The ideal solution would be to store profiles in a database that supports basic querying and filtering. We use Google’s Cloud Profiler, but instead of relying on their somewhat limited client libraries, we take advantage of their “offline API,” which allows us to ship existing .pprof files to Google:
The main benefit of sending profiles to remote storage compared to simply storing them locally is the ability to aggregate multiple profiles into a single view.
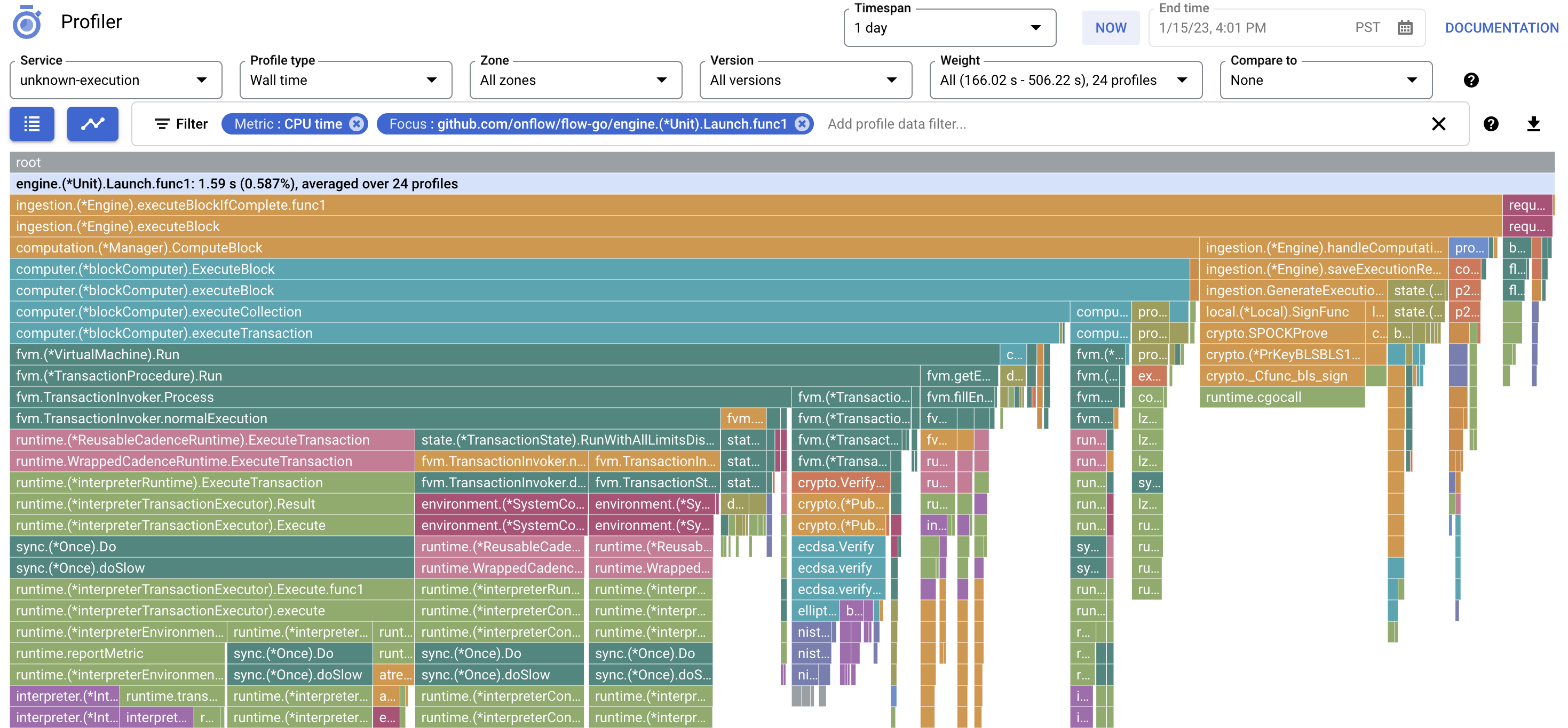
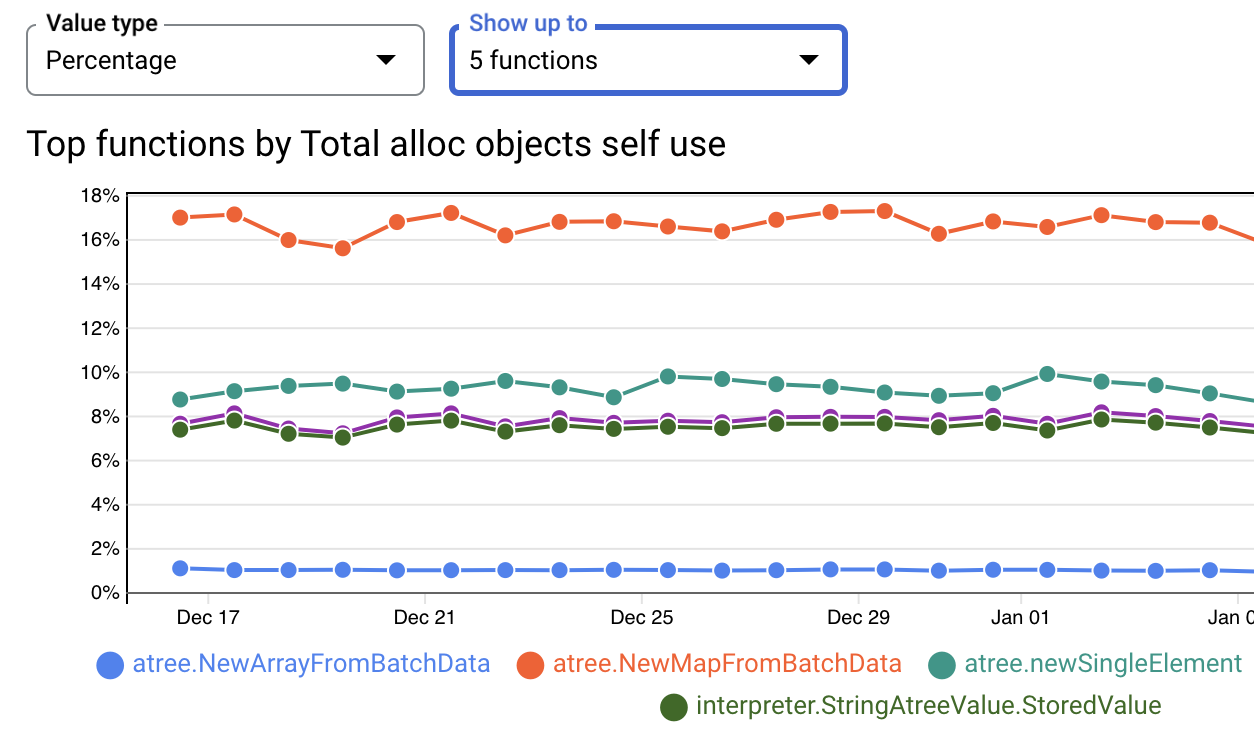
Additionally, it gives us the ability to look at profile trends over time.
Sadly, the Google’s "Offline" API is heavily rate- and size-limited and appears to be generally unsupported, so we are actively exploring alternatives. Since we are already using the Grafana stack, we are keeping an eye on Phlare’s development; it looks like a very capable replacement:
.gif)
Connecting profiling with tracing
We've invested a lot of effort in the user experience of performance analysis, ensuring smooth transitions between logs, traces, and metrics. However, profiling data is currently a unique challenge. To address this, we're exploring pprof.Do (or alternatively, pprof.SetGoroutineLabels at a lower level). This would enable us to create a connection between profiling and tracing that is currently missing.
Labels have a few drawbacks: they are not supported for all profile types and can increase profile size, so be mindful of label cardinality.
You can add arbitrary labels here, which is especially useful in multi-tenant environments. For example, you can annotate pprofs with a tenant's UserID and TeamID. Even for single-tenant setups, annotating profiles with EndpointPath may provide additional insight into CPU usage.
fgprof
Go's default profiler has a downside of only being able to view either On-CPU or Off-CPU time. Felix Geisendörfer’s profiler, fgprof, solves this issue by providing a single view that captures both.
Continuous Profiling
Profiling is now cheap enough that many companies provide libraries for continuous profiling in production, which has become a trend. Notable examples include Pyroscope, DataDog, and Google.
Rather than embedding a profiler into the codebase, Grafana Phlare employs an agent model that periodically scrapes Go's pprof HTTP endpoints located at /debug/pprof/:
eBPF-based Profiling
All profiling features above require some kind of instrumentation in the binary, whether it be an HTTP endpoint or a continuous profiling library. Recently, there has been a trend in observability towards instrumentation-less profiling enabled by eBPF.
For instance, Parca enables you to observe uninstrumented C, C++, Rust, Go, and more!
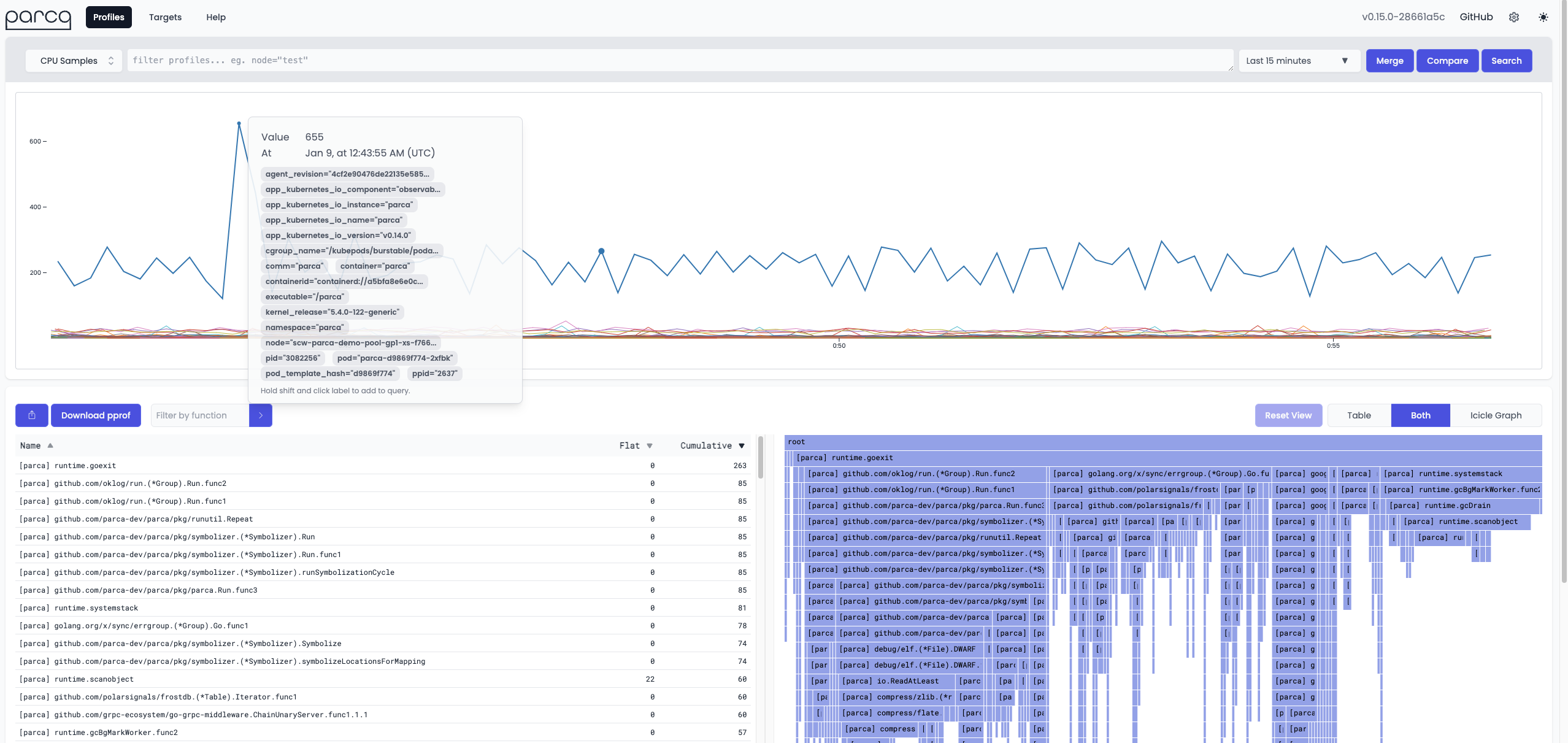
bpftrace/bcc profiling
Parca is relying exclusively on perf_events which is totally safe. Meanwhile, if you try a naive profiling approach utilizing uprobe / uretprobe with either bcc or bpftrace on a Go application you will likely encounter a SIGBUS due to Go's stack copying.
Microbenchmarks
Microbenchmarking in Go is a well-known practice, so there's not much to say about it. However, there are a couple of things worth mentioning. Firstly, it's recommended to use test.benchmem and run '^$' when running microbenchmarks.
Secondly, benchmark results should only be considered valid when -count is greater or equal to 10:
Finally, the benchstat tool (or similar) should always be employed when analyzing a single benchmark result to enhance readability and guarantee the absence of noise in the environment:
Noise can be a serious problem in the benchmarking environments. LLVM project has great documentation on how to tune Linux systems for less than 0.1% variation in benchmarks.
Additionally, when making comparisons, especially when claiming performance improvements, it is essential to show statistic:
Don't be shy about adding custom metrics to your tests to gain more insight into your performance reports from critical sections. Utilize b.ReportMetric and b.ResetTimer to optimize them.
It would be nice to have an open-source or SaaS tool that could gather and track microbenchmark results over time for a Go repository; however, we did not find one.
Blackbox Performance Tests
While there are a variety of tools for end-to-end performance testing web applications (e.g., we use grafana/k6 for testing ours), complex systems such as compilers or databases require custom blackbox tests, also known as macrobenchmarks. Here are a few good examples of automated macrobenchmarks in large open source projects (the benchmark frameworks themselves are also open sourced).
Vitess, a distributed database, has a very comprehensive (albeit slightly noisy) nightly performance test that tracks both micro- and macro-benchmark results. The test framework is open sourced at https://github.com/vitessio/arewefastyet.
Rust is another good example of an excellent benchmark framework for all kinds of compiler-specific tests done on a per-commit basis. It is also open sourced at: https://github.com/rust-lang/rustc-perf.
Our end-to-end setup is relatively trivial compared to these two, but still has a couple of interesting details. One of them is detecting the system overload point. Since blockchain is asynchronous and can queue transactions on multiple layers in our end-to-end macrobenchmark, we need to find the maximum transaction-per-second value that blockchain can handle without excessive latencies. We used to use TCP's additive-increase/multiplicative-decrease (AIMD) algorithm for that, but it was quite slow to converge. Recently, we switched to a PID controller (a PD controller, to be exact) instead, which has a nice property of quickly converging to the desired queue size while also not overshooting too much:
If you're interested in introducing PID controllers into your own systems, Philipp K. Janert's book, "Feedback Control for Computer Systems: Introducing Control Theory to Enterprise Programmers," is a great place to start. If you're more of a visual learner, the first couple of lectures from the "Understanding PID Control" YouTube playlist are also a great introduction. Just keep in mind that this is the MATLAB channel, so it goes deep quickly. You've been warned =)
Future work
Here we’ll go over things that we are planning on adding to our performance observability toolkit this year.
Bottleneck detection through slowing things down
It can be difficult to speed things up, but slowing them down is relatively straightforward. Therefore, one way to identify bottlenecks is to try slowing system components by 1ms, 5ms, 50ms, 250ms, etc., and measure the benchmark results. Then, extrapolate the function back to -1ms, -5ms, -50ms, etc. This method is approximate, but it works well for small values.
Casual profiler
A casual profiler is another active method and a more precise generalization of the previous one. Instead of slowing down the component of interest, it slows down everything else around it, thus emulating the speedup of the component being tested.
If you are interested in casual profiling there is a good video introduction to in “Coz: finding code that counts with causal profiling” (SOSP'15).
Automatic critical path analysis
Analyzing the critical path of a large-scale distributed system can be challenging. In their OSDI’14 paper, "The Mystery Machine: End-to-End Performance Analysis of Large-Scale Internet Services," University of Michigan and Facebook proposed a way to identify the critical path passively by observing logs (which are likely more similar to traces nowadays). This approach has the benefit of stacking nicely with both tracing and profiling infrastructure.
Appendix A. AI-driven blogpost editor.
Not related to Golang observability, but generally applicable to those who write blog posts: English may not be your native language, so first drafts of blog posts can be quite painful for an editor to fix. This often requires multiple hours (and likely even a bottle of whiskey) to put back forgotten articles, rephrase sentences, fight the urge to send me a Conjunction Junction video, fix punctuation and idioms. Modern language models can take away much of this pain. For example, the first pass of editing this post was done by text-davinci-003 (talk about overkill!) with the following prompt:
You are a technical blog editor reviewing a post about "Improving Observability of Golang Services." Please, rewrite the following paragraph correcting spelling, idioms, punctuation, and word choices as necessary. Combine, split sentences, or rewrite to increase clarity when needed. Don't make it too dry, humor is fine.