

Jolteon: Advancing Flow’s consensus algorithm

The consensus algorithm is the heart of any blockchain. It provides the fundamental guarantees of safety, liveness, and decentralization which enable the applications built on top. In January 2023, Flow upgraded to the Jolteon consensus algorithm. This upgrade results in about 33 percent faster block and transaction finalization times, as well as faster network upgrades. This translates into user interactions being confirmed more quickly and higher overall system stability and availability.
Background
Since Flow's launch in 2020, it has used a consensus algorithm from the HotStuff family of Byzantine-fault-tolerant (BFT) algorithms[1]. HotStuff provides many useful properties in addition to the core requirements of a consensus algorithm:
- Deterministic Finality - Blocks which are marked as finalized by the algorithm are guaranteed to never change.
- Optimistic Responsiveness - In the happy path, the algorithm will operate as quickly as the network allows, as opposed to needing to wait a fixed period of time for each block.
- Pipelined Block Production - Each new proposal simultaneously extends the chain and help to finalize a previous block.
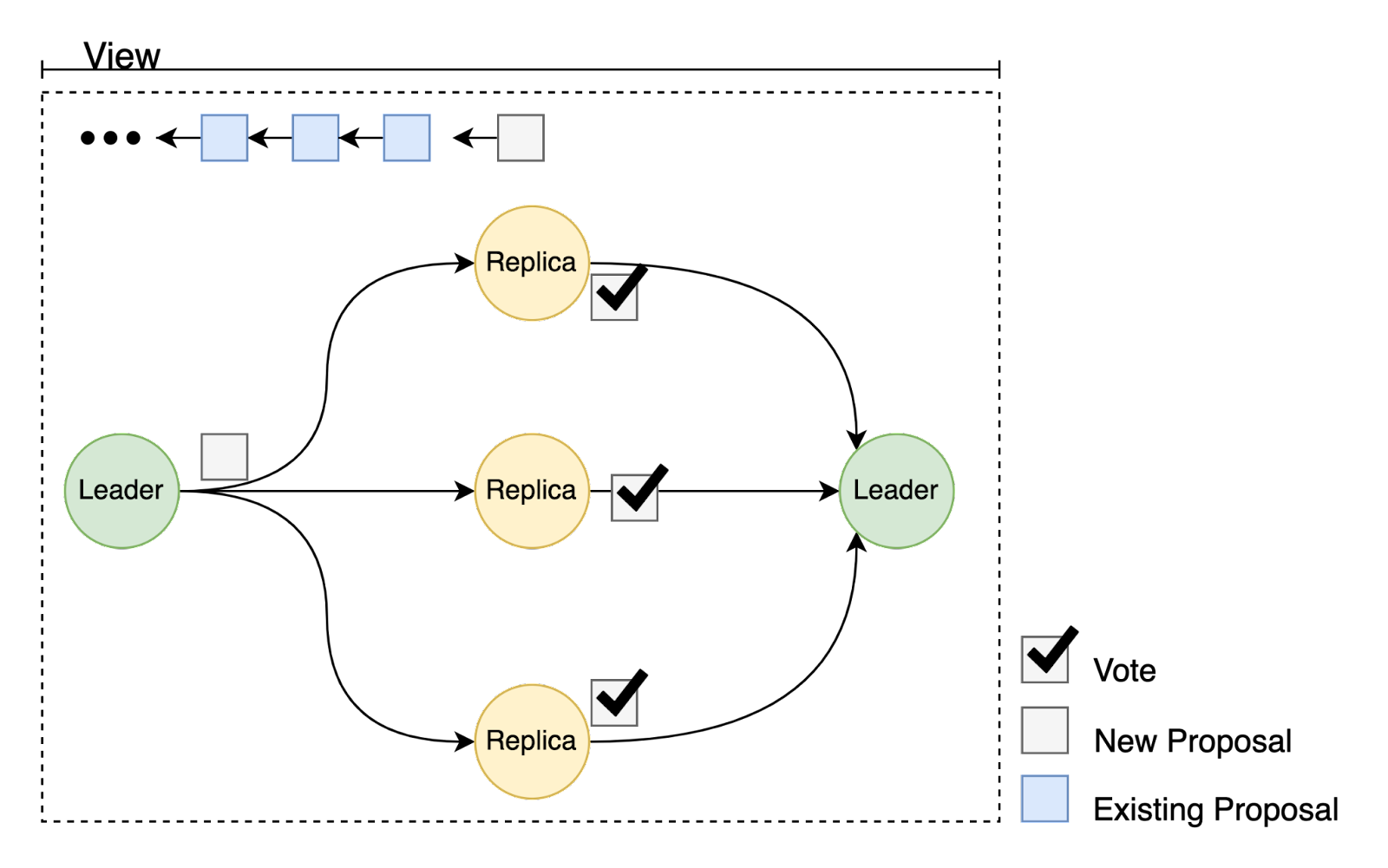
The HotStuff protocol proceeds in a series of rounds (often called views) in which one node is the leader and may propose a new block by extending a previously proposed block. A new leader is selected for each subsequent round. (In the following diagrams, nodes other than the leader are referred to as replicas.) In the happy-path, a supermajority[2] of the committee will accept the block by voting for it. We refer to this as a successful round.
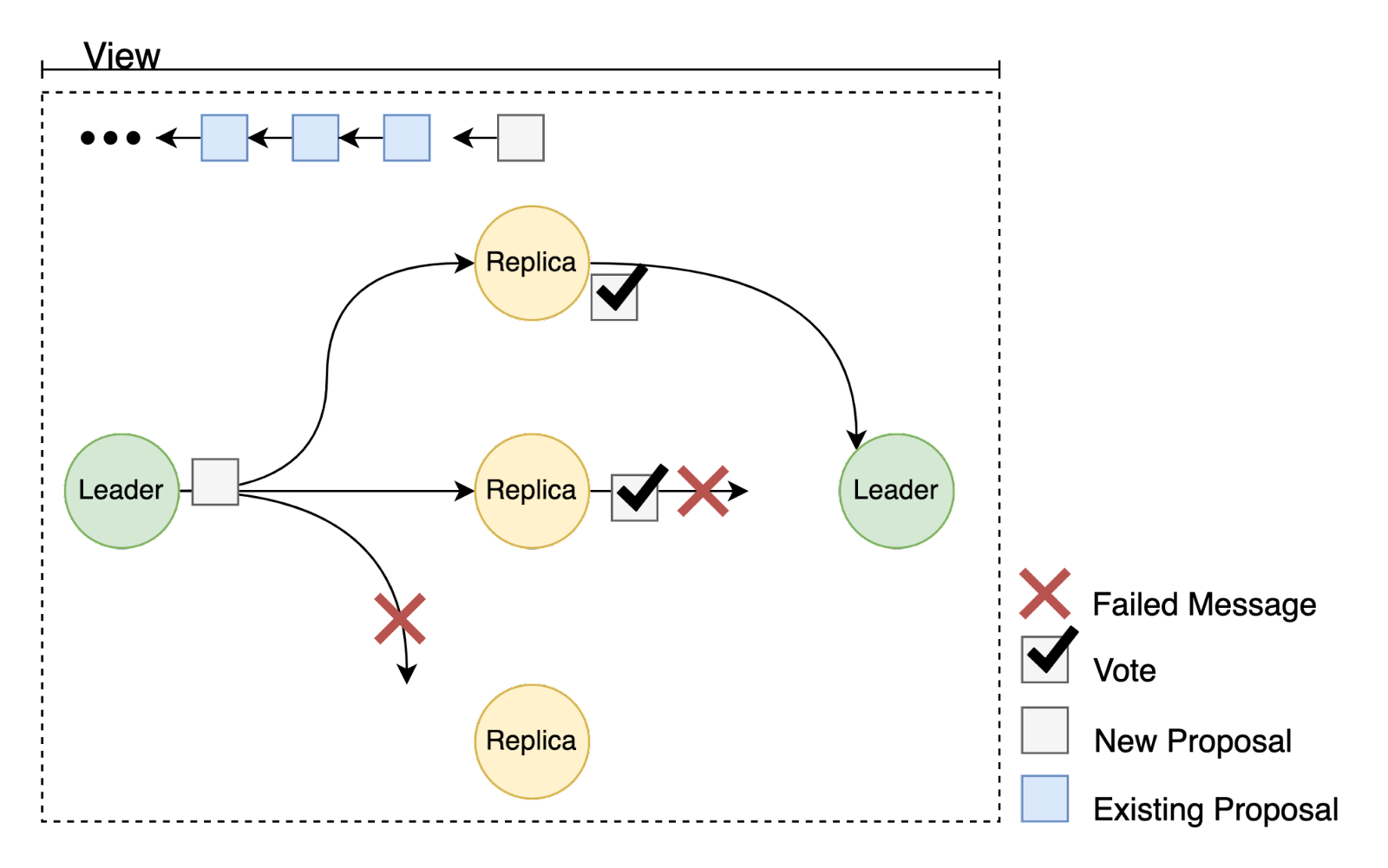
If no block is proposed, or not enough votes are gathered to reach a supermajority, then we consider the round to have failed. The protocol will try again with a new proposal in the next round.
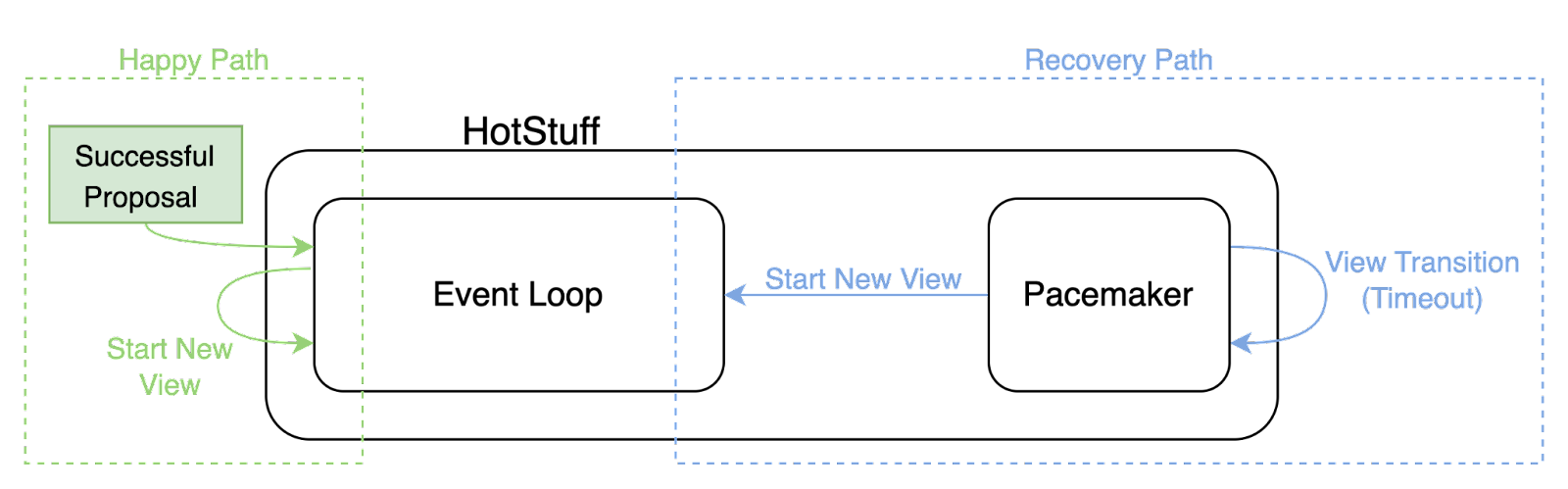
Of particular interest to the latest upgrade is a component in HotStuff called the Pacemaker. Each node maintains a local current_view variable which is incremented when observing successful proposals for their current (or greater) view, or when indicated by the Pacemaker. The Pacemaker is responsible for ensuring individual nodes agree on the current view, so they can make progress together.
This is particularly important in the unhappy path of the protocol, to recover from an offline leader or transient networking failures. If there was a successful proposal in every round, the Pacemaker would never be called upon. The Pacemaker's job is to determine when to proceed to the next round, in the absence of a successful proposal for the current round.
Challenges
Until now, Flow has used a Passive Pacemaker, which operates without exchanging any messages with other nodes. It decides whether to skip the current view based on knowledge of whether previous views succeeded and an exponential-increase timeout function. This makes it relatively simple to implement, but also limits its effectiveness, especially in edge cases. As we'll see later, it also has indirect consequences to performance which are not immediately obvious.
To illustrate the limitations of the Passive Pacemaker, suppose a group of friends is organizing dinner. Alice, Bob, Charlie and Eve go to dinner every Friday. They take turns and each week one of them decides on a restaurant. This Friday, it is Eve’s turn, but Bob hasn’t heard anything from her. He isn’t sure whether he was the only one to miss Eve’s call. It could also be that Eve is camping and has no reception, in which case no one would have heard from Eve.
In this case, their usual process is that the next person in line (Alice) would pick a restaurant. Intuitively, Bob would call Alice and Charlie, confirm they also haven’t heard from Eve, then agree to skip Eve’s turn and let Alice pick a restaurant. However, in the more restrictive communication scheme of the Passive Pacemaker, this fallback call wouldn’t be allowed. All Bob can do is wait long enough until he is quite sure that Eve won’t call.

Before discussing the actual upgrade, let's consider what an optimal Pacemaker would look like. In order to make progress, a supermajority of nodes must be in the same view when a proposal for that view is produced, so an optimal Pacemaker would ensure that all nodes maintain a consistent view. When a view can't proceed because of a leader failure, an optimal Pacemaker should skip that view as quickly as possible to avoid waiting for a proposal which will never arrive.
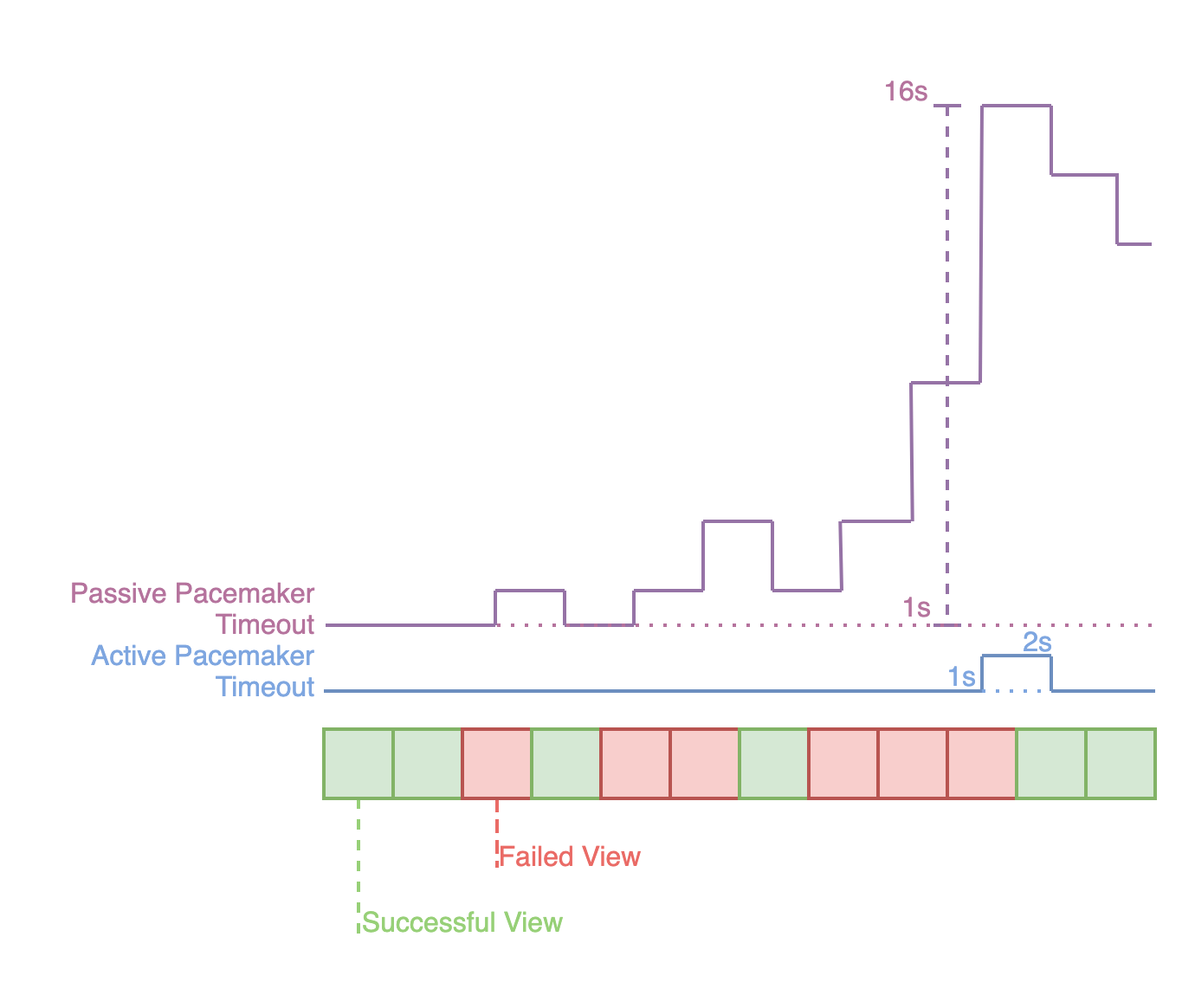
Because of the impracticality of coordinating clocks in a decentralized system, let alone one with Byzantine nodes, the Passive Pacemaker can't keep all nodes on the same view. When timeouts are low and most views result in a successful proposal, the Passive Pacemaker performs quite well. However, when several views fail and more time passes without a successful proposal, the finalization rate can be severely impacted because each consecutive failed round exponentially increases the timeout for the next round.
At the limit, these challenging network conditions amount to a system outage.[3] Fortunately such failure scenarios are rare. However, over longer periods unplanned outages are inevitable and must be planned for. Similar conditions can also occur during planned network upgrades (called “sporks” for Flow[4]) as different node operators bring their nodes online at different times.
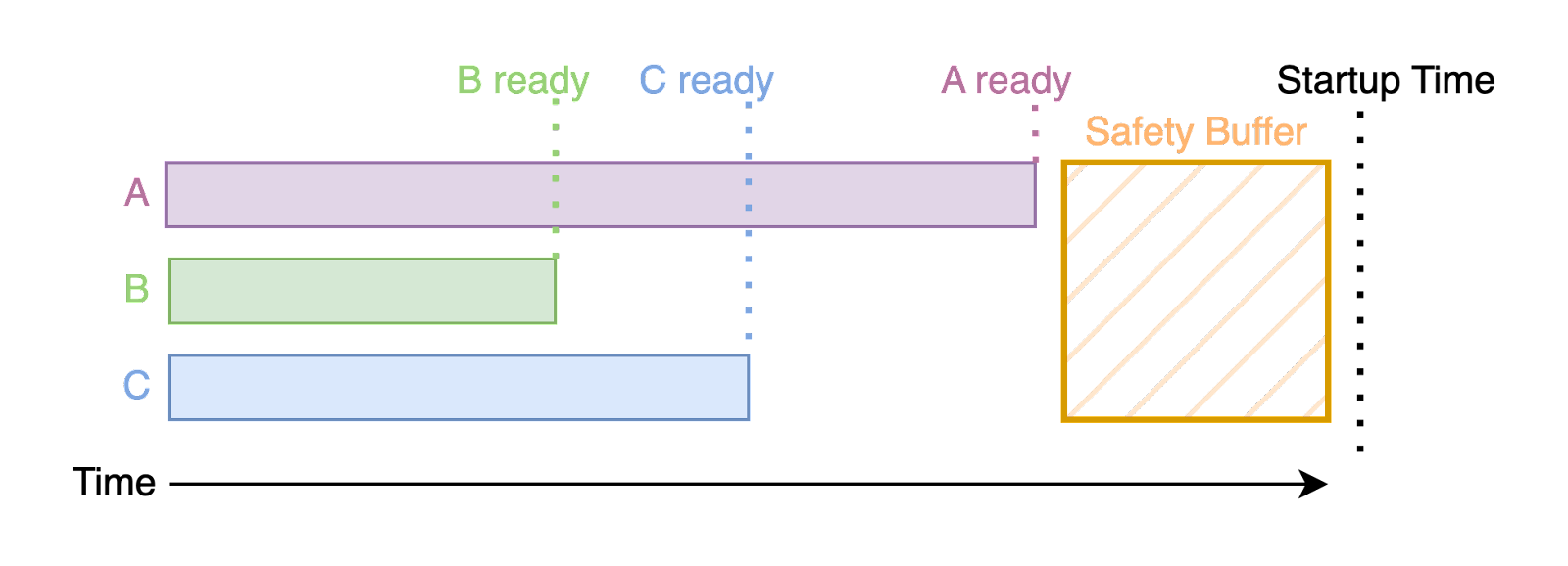
When these conditions occur, the network is split into groups, each with less than a supermajority of nodes, where different groups have different view and timeout values. Since we require a supermajority of nodes to be in the same view, no progress can be made until enough of these groups converge on the same view. Convergence is made much more time-consuming by the lack of active communication. The Passive Pacemaker is tuned so that nodes in higher views will timeout more slowly, so convergence will happen eventually, but "eventually" can be a long time. When groups differ by as little as 10 views (one group has current_view=n and a different group has current_view=n+10), the time to recovery can grow to minutes or even hours.
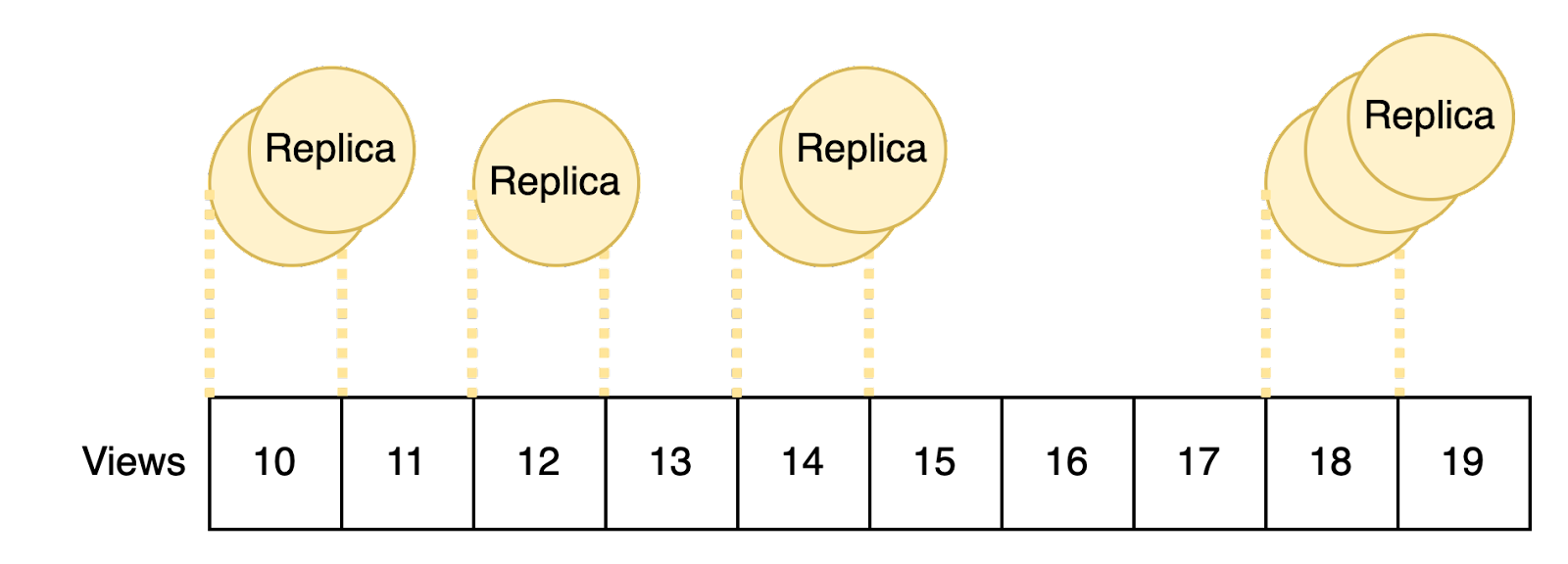
When view divergence occurs, the recovery time can be lowered by adjusting views and timeout values on different cohorts of nodes to manually increase the rate of convergence. This strategy can work, but it is a sensitive process to get right. It requires coordination between different node operators and an understanding of the Passive Pacemaker's mechanics. The wrong adjustments can just as easily make the problem worse and lengthen the outage (which we have experienced first hand!). Although this mitigation can help, system recovery is generally too unreliable and impractically long.
To minimize the risk of view divergence during sporks, operators agree in advance on a startup time and configure their nodes for a coordinated startup at this time. This has worked well, but introduces additional downtime to the spork process. The startup time needs to accommodate the worst-case timing to ensure all operators are ready prior to startup. If the startup time needs to be pushed back for any reason, this requires a round of manual coordination and to accommodate worst-case timing again.
The Jolteon Consensus Protocol
Jolteon was originally published June 2021 by Meta’s blockchain research team, Novi, and academic collaborators. Meta’s team (now called Diem) implemented Jolteon and named it DiemBFT v4, which was subsequently rebranded as AptosBFT without further modifications. Conceptually, Jolteon (DiemBFT, AptosBFT) belongs to the family of HotStuff consensus protocols. Jolteon follows the HotStuff framework of pipelined block finalization, but adds two significant improvements.
Active Pacemaker
The Jolteon algorithm's first upgrade is the introduction of an Active Pacemaker. The Active Pacemaker extends the protocol to introduce an active recovery mechanism for views without a successful proposal. When a node times out, rather than immediately transitioning to the next view, they will first broadcast a timeout message including information about their current view and last observed successful proposal. Individual nodes will not leave a failed view until they observe timeout messages from a supermajority of nodes.
This explicit timeout step ensures that individual nodes only skip failed views based on evidence of a collective agreement to skip the view rather than isolated local timeouts. The result is that a supermajority of nodes must be within one view of each other at all times[5]. This effectively eliminates the possibility of view divergence and its related negative impacts.
Returning to the example of friends organizing dinner, this is analogous to Bob being able to fallback to direct communication with Alice and Charlie when he does not see Eve’s message. They can quickly determine whether Eve has gone camping or whether Bob just missed her call, and decide how to proceed.
During sporks, nodes may start up as soon as they are able. At first, when a supermajority is not online yet, these nodes will not skip any views. As soon as a supermajority of nodes come online, the network will begin finalizing blocks without manual coordination or waiting for view convergence. Similarly, for the duration of any outage that may occur, all honest nodes will remain in the same view, even if they cannot finalize any blocks. As soon as the root cause is resolved, finalization can immediately resume. This translates to shorter sporks, less operational overhead, and faster recovery from unexpected outages.
In addition, since failed views can be explicitly handled while maintaining view synchronization, we have more flexibility to adjust the timeout configuration. In any system, especially one which must account for the presence of Byzantine participants, failures are expected. Where each failed view with a Passive Pacemaker would cause a subsequent failed view to take twice as long to time out, the Active Pacemaker can allow a few consecutive failed views to pass without increasing the timeout, then only begin increasing the timeout when it appears that network conditions have durably degraded.
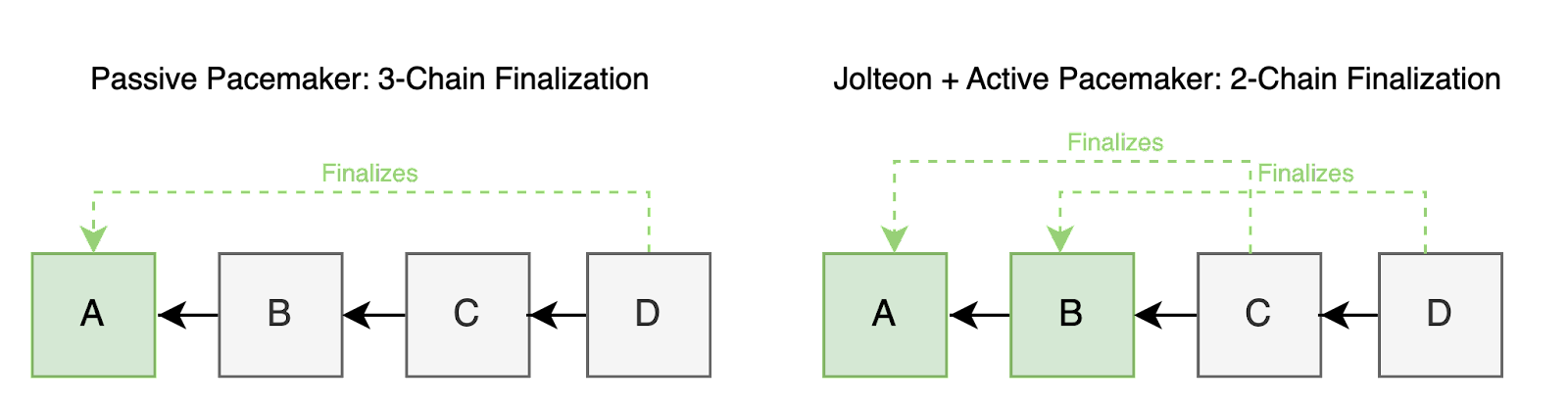
Finalization Speed
Flow uses a flavour of the HotStuff consensus algorithm which provides deterministic finality for a block once enough confirmations of that block have been incorporated into the chain. When a block is finalized, it means that the transactions within have been irrevocably accepted by the network[6], so the time required to finalize a block is directly related to the user's experience of how long their operations take to complete.
Since HotStuff is a pipelined algorithm, each confirmation of a previous block is simultaneously a newly proposed block containing new user transactions. This also means that each confirmation for a block takes as much time as proposing and voting for a new block. On Mainnet this is a little over one second.
Up to this point, Flow's consensus has required 3 successful confirmations for a block to be finalized. With the Jolteon upgrade, finalization can be achieved after only two confirmations. This difference is achievable because of the introduction of the Active Pacemaker. The addition to the protocol of explicit communication about failed views changes the logic of safety to enable individual nodes to convince themselves of consensus on a block more quickly.
Let's consider an example to illustrate how active communication in the recovery path enables faster finalization in the happy path. In the Asterix comics, the Roman armies are attempting to attack the Gaul village. The Romans believe that they will only succeed if they attack at the same time, so their armies must agree on when to attack. Each army is hidden away on separate sides of the village, so they must communicate using a carrier pigeon. Sometimes carrier pigeons get lost or delayed, despite their best efforts.
Caesar’s Proposal (0-Chain)
At sunrise, Caesar sends a proposal to attack at 8PM to all the armies. Our army sends a response saying that we are ready to attack at 8PM. At this point, we know only that our army and Caesar agree on the attack time. We aren't sure whether the other armies received Caesar's proposal, or even if Caesar received our response, so it isn't safe for us to commit to an attack.
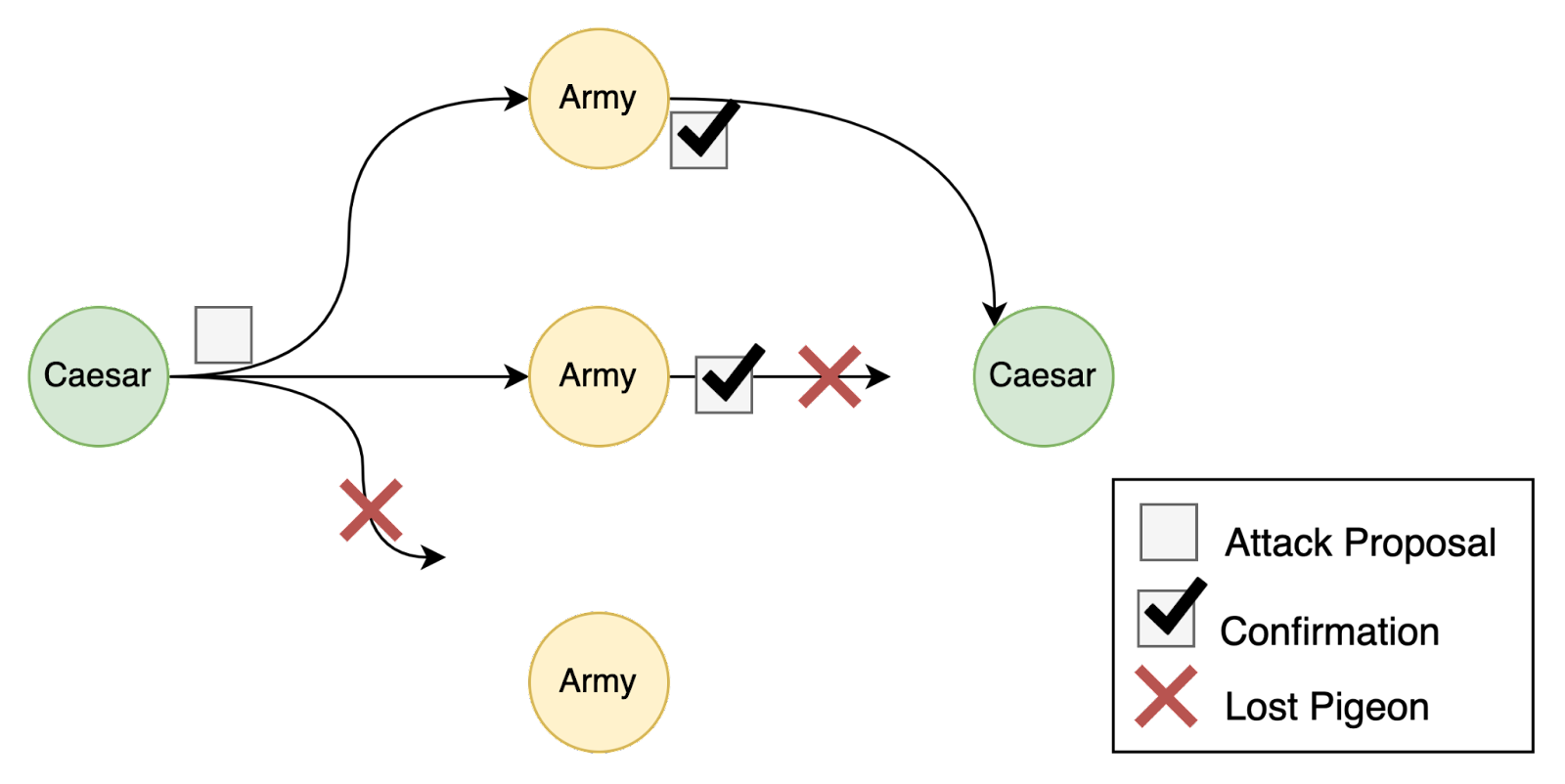
We refer to our local knowledge as a 0-chain because we have a proposal but no confirmations for it.
1st Confirmation (1-Chain)
At noon, we receive a second message from Caesar saying that all the armies have confirmed they could attack at 8PM. We send a response acknowledging this. At this point, we know that Caesar received a confirmation for 8PM from all the other armies. But what do the other armies know?
If Caesar's second message failed to reach the other armies, then those armies would be in the same position we were in after receiving only the proposal, and would consider it unsafe to commit to an attack. At this point, we know that all armies have relayed they could be ready to attack at 8PM. However, we aren't sure whether the other armies know this. So it is still not safe for us to commit to an attack.
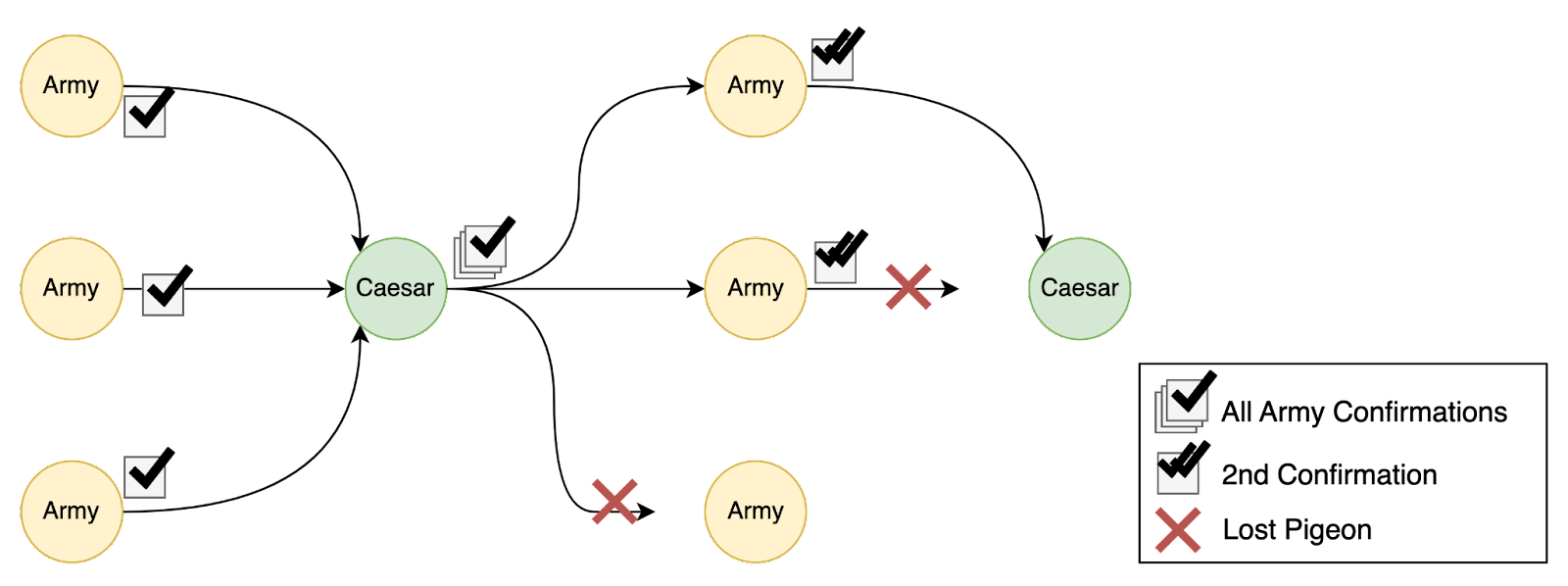
We now refer to our local knowledge as a 1-chain, because we have a proposal and one round of confirmations for the proposal.
2nd Confirmation (2-Chain)
Finally, as twilight falls and our soldiers grow anxious, we receive a third message from Caesar saying that all armies have acknowledged his second message. At this point we know that all other armies are aware of Roman commitment on 8PM. This third message is evidence of Roman commitment to attack.
It seems like we should be able to attack now, but what if another army didn't receive Caesar's third message? Then they would have the same knowledge we had at noon, after receiving the second message. In fact, after each message we receive, we can only know that all armies received the previous messages. In the worst case, the most recent message may only have reached us.
If all armies had received the third message, then all armies would have the information they need to commit to the attack. In other words, the evidence to convince all armies to commit exists. The problem is making sure that all armies see the evidence.
So, what do we do? One option is for Caesar to send yet another message, once he has received another round of confirmations from all armies. This message will inform us that all armies have seen the evidence of Roman consensus they need to commit to the attack. This would create a 3-chain (3 consecutive confirmations for the proposal), which is sufficient to finalize the proposal without active fallback communication.
But what if the armies had the ability to communicate amongst themselves, only if they failed to receive timely communication from Caesar? Video-conferencing is a new and very expensive technology in the Roman Empire, so the Treasury will only approve its use in the most dire of circumstances. They strongly prefer pigeons.
With this ability to fallback to group communication at our disposal, all our army needs to commit to the attack is to know that the agreement evidence exists (2-chain). Hopefully Caesar's final message, containing this evidence, will reach all armies. Failing this, we will be able to communicate our copy of the evidence to the other armies with a quick video-conference.
Conclusion
This upgrade represents a significant step forward in Flow’s evolution, bringing the latest advancements in consensus research to a production environment. The Active Pacemaker improves reliability by facilitating faster recovery from network upgrades and reducing the likelihood and impact of unplanned outages. This in turn enables a 2-chain block finalization rule which results in approximately a 33 percent faster transaction finalization. Both improvements ultimately provide a more robust platform for users and application developers.
Thank you to Alex Hentschel, Jerome Pimmel, Misha Rybalov, Tarak Ben Youssef, and Yurii Oleksyshyn for contributing to this content.
Notes
[1] A Byzantine node may fail to receive or send messages (like a node affected by benign networking failure), but may also break protocol rules, such as sending different proposals to different nodes, voting for multiple conflicting proposals, or attempting to impersonate a different node.
[2] A supermajority is formed by strictly greater than 2/3s of the committee. In particular, with a chosen “Byzantine threshold” f, a committee must have at least 3f+1 nodes and a supermajority is formed by 2f+1 nodes. For example, a committee with 4 nodes can tolerate at most 1 Byzantine node; a committee with 100 nodes can tolerate at most 33 Byzantine nodes.
[3] For example, suppose we start with a timeout value of 2 second and are facing a series of 11 consecutive offline leaders. After the 10th failed view, a consensus’ node timeout will increase 2s * 2^10 = 2048s. Hence, the node will wait 34mins in view 11 alone, before giving up and transitioning to view 12.
[4] A fork occurs when a breaking change is introduced to a blockchain — if some nodes have not upgraded, then they may disagree about what is a valid extension to the chain and build a conflicting version of history after the upgrade. A spoon occurs when the application state of a blockchain is used to initialize a new blockchain, rather than initializing from an empty state. We use the term “spork” because network upgrades in Flow combine both these properties, enabling speedy upgrades to both the protocol (how nodes communicate with one another) and execution environment (how transactions are executed and application data is stored).
[5] This supermajority is the set of nodes which contributed either a vote or a timeout used to end the previous round. Its members may change from round to round. This has an impact on security of different Byzantine threshold assumptions. The highest possible Byzantine threshold is f Byzantine nodes with at least 2f+1 honest nodes, but a given system may or may not allow for these f nodes to change from time to time.
[6] Technically it means that a final order for the transactions has been determined, so the transactions’ results are fixed and knowable, but not yet available to clients. To be completed they must be executed and sealed as well, but finalization is a critical step in the transaction processing path.