

Smarter State: Optimizing Flow for Scale, Speed, and Sustainability

Scaling a blockchain from millions to billions of users is a matter of continual evolution, not just sudden breakthroughs. It emerges from persistent, deliberate refinements at every layer of the protocol. Some of these changes may seem incremental, but their benefits are significant when applied at global scale.
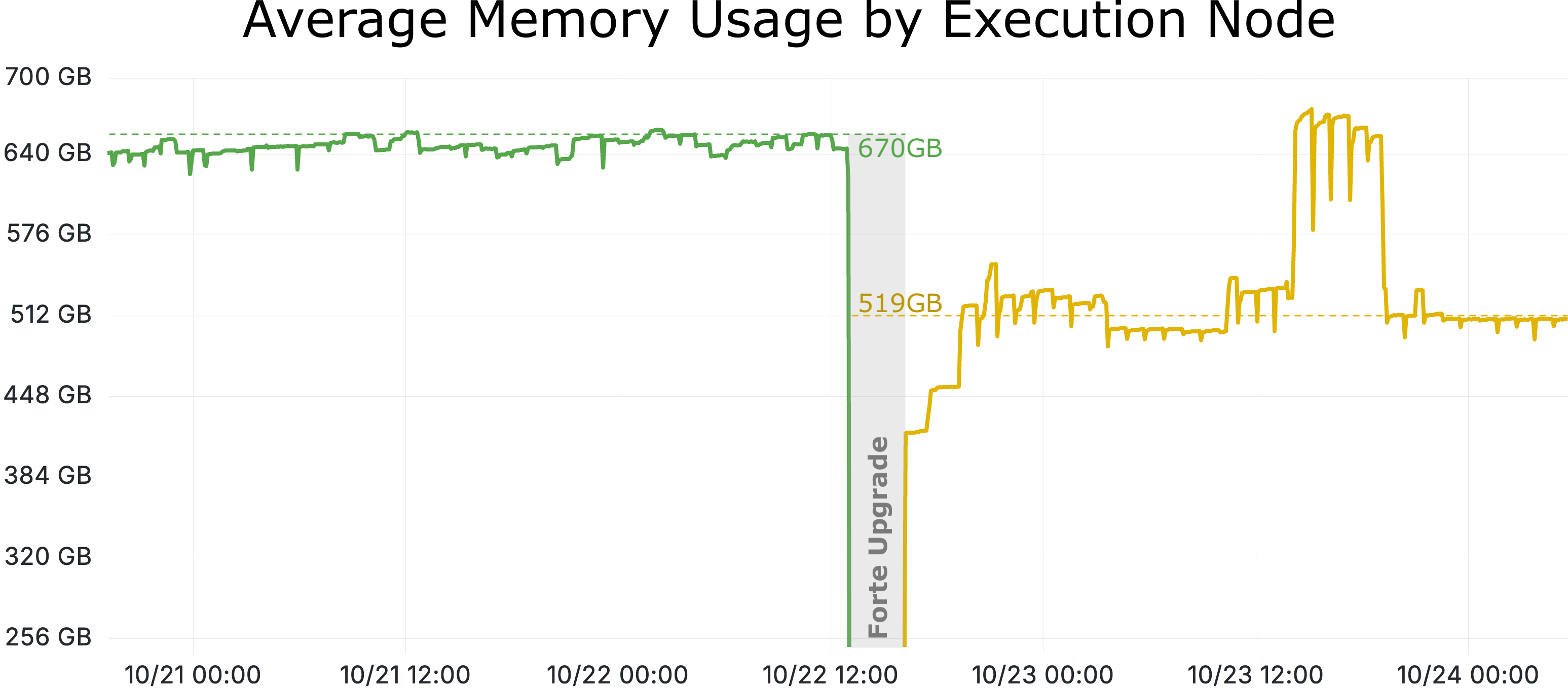
One recent example is Flow’s new account key deduplication, an optimization that reduces the execution state by 28.8 GB, or more than seven percent.
The execution state is where Flow stores user data: account keys, token balances, smart contracts and their data, as well as all other on-chain resources such as NFTs. Persisting this information as flat key–value pairs would be simple and compact, but would make verification impractical, a process central to blockchain security.
To make verification efficient, the data is organized into a Merkle trie (MTrie), a tree-like data structure where each vertex stores the secure hash of the data beneath it. Each object in the execution state is represented in the trie as a compact data blob called a payload. When values change, nodes only need to recompute hashes along the affected paths. While the trie enables efficient state verification, it also requires additional data: each new payload adds its own path in the trie, and as the total number of payloads grows, all paths become longer. Therefore, reducing the number of payloads in the trie significantly lowers memory, disk, and network load across all node types that manage the execution state.
Each account key is represented by a compact payload of 72–78 bytes, while the trie required an additional 192–288 bytes of cryptographic metadata that make the state verifiable. By rethinking how account keys are stored, the Forte upgrade removed over 86 million data payloads and 77 million duplicate public keys. The result is roughly 211 million fewer trie vertices, reducing the amount of data that must be hashed, stored, and synchronized. Account key deduplication, combined with other optimizations described below, translates into lower memory usage (around 150 GB less per Execution Node), reduced energy consumption, and greater operational headroom for future growth. Over time, these improvements compound to deliver lasting gains in operational efficiency, allowing Execution Nodes to handle significantly more data than nine months ago without adding extra RAM.
Account Keys and Sequence Numbers: Parallel Lanes for Secure and Scalable Transactions
To understand why duplicate keys exist in the first place, it helps to look at how Flow manages transaction ordering and replay protection.
A replay attack occurs when the same transaction is executed more than once. Without protection, an attacker could re-submit a valid transaction to repeat an action, such as transferring tokens. Most blockchains prevent this by assigning a unique counter to each transaction. Ethereum’s nonce, for example, is a unique counter in every account that increases with each executed transaction.
Flow adopts the same principle but extends it to support greater flexibility and scalability. Instead of a single counter per account, each account key on Flow has its own independent sequence number. This design brings several practical benefits:
- Higher throughput for applications that send many transactions simultaneously, such as games, marketplaces, or custodial services.
- Simpler key management for wallets and contracts that delegate signing to different devices or backends.
- Granular security control because each key can be independently rotated, revoked, or weighted without affecting others.
You can think of these per-key sequence numbers as parallel lanes for signing and submitting transactions, enabling higher throughput and more flexible account management. (See Flow accounts documentation for details on multi-key accounts.)
Smarter Storage
The ability for Flow to handle many keys per account brings flexibility and throughput, but it also increases the amount of on-chain data that must be stored and maintained. Each key adds payloads to the execution state, so even small inefficiencies multiply across millions of accounts. Designing an optimization that improves performance and storage efficiency while preserving clarity required careful engineering.
This new design separates each key into three components: the public key itself, its metadata (such as weight or revoked status), and its sequence number. This structure makes it possible to detect and store duplicate keys only once, then reference them wherever they reappear. To maximize efficiency, additional metadata is stored only when an account actually needs it, while lightweight accounts with a single key remain virtually unchanged.
The impact is substantial: efficient duplicate detection, compact key metadata, and adaptive storage strategies minimize redundant state data and storage overhead for nearly all accounts. In the following sections, we will explore these design choices and innovations in detail.
1. Key deduplication
The primary challenge in key deduplication is achieving meaningful storage savings across all accounts while keeping the system efficient. Some accounts have only a single key, while others may contain thousands of unique or duplicate keys. To understand this challenge, let's examine the deduplication process, which involves two main steps:
- Detection: The first step is identifying whether an identical key already exists. This begins by matching the new key’s digest, a short hash used as a compact reference to the key, against stored key digests, followed by comparing the full key only if a matching digest is found.
- Storage: If the new key is identified as a duplicate, the system stores a reference to the existing key instead of saving it again. Otherwise, it saves the new key digest and the corresponding public key.
This detection mechanism depends on storing key digests. If every account stored digests for all its keys, the detection rate would reach 100%, meaning every duplicate key could be identified as such.
However, about 90% of accounts do not contain any duplicate keys. For them, storing key digests provides no savings, only overhead. Even for accounts with small fractions of duplicates, the cost of storing and comparing digests may outweigh the benefits of deduplication. As more key digests accumulate in an account, deduplicating additional keys becomes increasingly work-intensive and could, in extreme cases, exceed the computational limit of a single transaction.
To balance efficiency across all accounts, Flow limits how many key digests are stored. The detection rate is intentionally set below 100%, similar to how compression programs/libraries don't use max compression by default. Currently, the system stores the last two key digests per account, which minimizes storage overhead while still capturing nearly all duplicate keys in practice.
2. References to stored keys
On Flow, each account key defines a separate “lane” for signing and submitting transactions, with its own independent sequence number counter. An account can have many such lanes, allowing multiple transactions to proceed in parallel. Different lanes can even share the same public key. To manage these shared keys efficiently, each Flow account maintains a reference list that records which lane (account key) use which stored key. This mapping deduplicates identical public keys where possible, reducing redundancy without affecting each lane’s individual sequence number or permissions.
In more detail, the reference list maps account key indices to stored key indices. When a new lane is added, the account key index increases sequentially, while the stored key index either points to an existing key (if it’s a duplicate) or increments from the last stored index when storing a new key.
For instance, consider an account with five account keys but only one unique public key. The first account key has an account key index of 0 and a stored key index of 0. The second account key has an account key index of 1, while its stored key index remains at 0. Consequently, the reference list for this account is [0, 0, 0, 0, 0], indicating that all account keys (lanes) utilize the same stored key at index 0.
The reference list is then compressed using run-length encoding (RLE), which replaces consecutive occurrences of the same value with the value and its repetition count. For example, the list [0, 0, 0, 0, 0] becomes “value 0, run length 5.”
RLE is efficient for long runs of identical values, but it is less effective when keys are mostly unique. For example, an account with five account keys and four unique public keys (the first two being duplicates) would have a reference list [0, 0, 1, 2, 3]. Here, RLE can only compress the initial duplicates [0, 0], leaving [1, 2, 3] uncompressed. As the number of unique keys in an account increases, this inefficiency grows.
In practice, account key indices are typically added in groups, either all controlled by the same key or each receiving a new one. To efficiently handle such mixed patterns, Flow developed an enhanced version called RLE++, designed to also compress sequences of consecutive values like [1, 2, 3]. In RLE++, the value marks the starting point of the sequence, and the run length indicates how many consecutive incremental values follow. For example, [1, 2, 3] is encoded as “starting value 1, run length 3.”
In summary, RLE++ combines standard RLE (for repeating values) with incremental encoding (for sequential values), allowing the reference list to be stored efficiently for all accounts.
3. Optimization for accounts with one account key
On Flow, around 65% of accounts have only one account key. Splitting this key into separate components would introduce unnecessary storage and processing overhead. Moreover, these accounts do not require a reference list, as there is a straightforward one-to-one relationship between the stored key and the account key.
To avoid overhead for these accounts, the account key at index 0 is always stored in a dedicated payload that directly includes its public key, signature and hash algorithms, key weight, revoked status, and sequence number. An account’s key metadata and reference list begin only with key at index 1.
In other words, single-key accounts retain the same straightforward structure as before, without any additional storage or performance cost.
4. Optimization for accounts with only unique keys
Roughly 90% of Flow accounts contain only unique keys, including the 65% that have just one key. For these accounts, maintaining a reference list adds unnecessary storage and processing overhead, as there is a clear one-to-one association between the stored keys and the account keys. Flow therefore defers creating a reference list until an account actually encounters a duplicate key.
With this optimization, the efficiency achieved for single-key accounts scales seamlessly to those with multiple unique keys, keeping storage compact and performance consistent across all accounts.
5. Optimization for sequence number payload
Every Flow transaction involves three roles: a payer, one or more authorizers, and a proposer. The payer’s signature commits to covering the transaction fees, and the authorizers’ signatures grant permission for the transaction to access or modify their account resources. By signing with a proposal key, the proposer account consents to the use and subsequent increment of that key’s sequence number, which prevents the transaction from being replayed. A single account can propose multiple transactions in parallel, each signed with a different account key acting as the proposer.
Flow’s multi-key and multi-sequence-number design delivers this flexibility at low runtime cost. In practice, only about 22% of keys are ever used to sign transactions as proposers. The remaining 78% serve other purposes, such as fine-grained access control to account resources, recovery or backup access, and multi-device authentication. The Forte upgrade leverages this insight by initializing sequence number payloads only when keys are first used as proposers. This small yet broadly applicable optimization benefits roughly 78% of account keys, reducing state size without altering transaction behavior.
In short, users retain the advantages of parallelism and replay protection, now implemented more efficiently for the vast majority of accounts and transactions.
The Future: From Smarter Keys to Simpler Protocols
The work behind account key deduplication is more than an isolated optimization. It embodies Flow’s core philosophy: absorb complexity into the protocol so developers can focus on creating great applications rather than managing low-level mechanics.
Looking ahead, our research explores a truly hands-off approach to replay protection, implementing it entirely at the protocol level without requiring client-side mechanisms such as sequence numbers or nonces. The concept builds on trie-based cryptographic set accumulators to track included transactions directly within the protocol, ensuring replay prevention happens seamlessly and securely under the hood.
Today’s sequence numbers already serve the network well, and optimizations like those in the Forte upgrade make them cheaper to maintain. The improvements now live on Flow mark another step toward a simpler and more efficient protocol.