

Advancing Protocol Autonomy with Data Integrity

From its conception, Flow was architected to be fully decentralized and Byzantine Fault Tolerant (BFT). The network has been developed with an incremental and evolutionary approach, systematically opening up participation while removing implementation shortcuts that rely on human coordination for security. Flow has already achieved decentralization and continues to advance toward full protocol autonomy, where all node types can operate permissionlessly and safely under adversarial conditions.
With each major upgrade, Flow makes significant progress toward this vision. Earlier milestones such as Application Layer Spam Protection and Dynamic Protocol State strengthened the network’s autonomy by enabling self-regulating and attack-resilient node behavior. The Forte release - which goes live on Flow on October 22nd, 2025, accomplishes another major milestone on the protocol autonomy roadmap by ensuring that all messages exchanged across the network are canonical, immutable, and cryptographically verifiable.
Part of the Forte upgrade includes a Data Integrity release. This improvement hardens the security of messages sent between nodes by making them canonical and immutable, and by enforcing these rules during the development process. It was the result of over a year of engineering effort and touched 6+% of the flow-go codebase. You can read the release notes here: flow-go v0.43.0.
Background
As a decentralized network, Flow depends on many nodes working together. Nodes coordinate by exchanging messages over an internal peer-to-peer network. If those messages can be altered without the sender or receiver noticing, safety and correctness are at risk.
Data integrity primarily addresses a class of issues where two different messages could be incorrectly treated as equivalent. It also improves safety across the message lifecycle by enforcing validation at trust boundaries and immutability after construction.
All messages are identified by a short ID string. Nodes use this ID as a shorthand and unique identifier for the message: every distinct message must have a distinct ID. To accomplish this, a message’s ID is determined by computing a collision-resistant hash function over the message’s encoded fields. If any field is excluded from the encoding, an attacker can modify that field without changing the message ID, which compromises message integrity and can act as an entry point for further attacks.
The goals of Data Integrity are simple:
- Deterministic Identity - An object’s ID commits to all fields that affect validation or semantics.
- Immutable Models - Objects are constructed once and then frozen. There is no mutation after construction.
- Uniform Validation at Trust Boundaries - All incoming messages are decoded into an untrusted representation and then validated through constructor functions before use.
- Early Detection - A custom linter blocks unsafe patterns during software development and build processes.
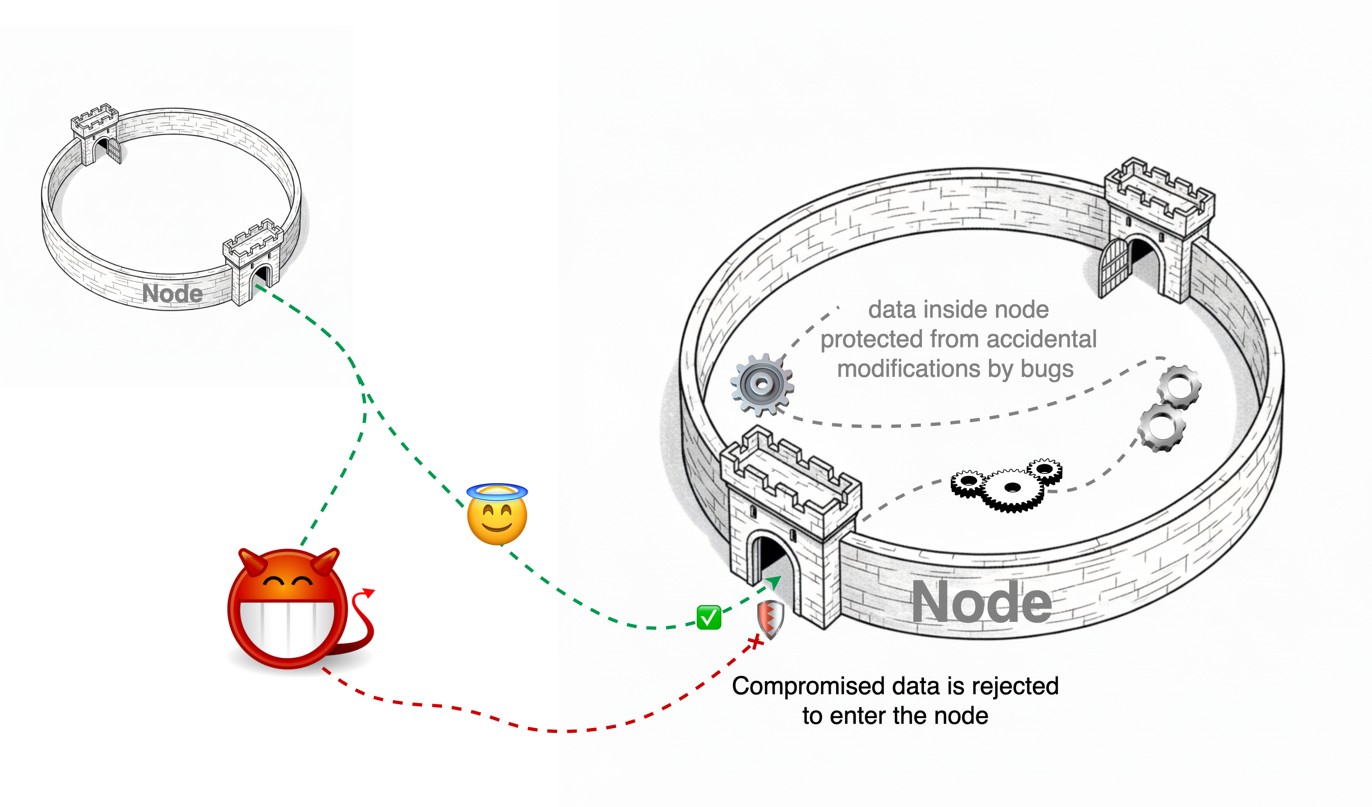
Together with existing message authentication, these changes make it near impossible for any node to accept or propagate a maliciously altered message. We reduce ambiguity and make the behavior of the system easier to reason about.
Collision-Resistant Message IDs
All message types and core internal models were audited to ensure ID functions are resilient to message tampering: that any change to a message or model results in a different ID.
As part of this work, we developed a generic testing framework called MalleabilityChecker to verify tamper resilience for all affected types on an ongoing basis. The MalleabilityChecker iteratively mutates all fields in a model and validates that the ID changes as expected. Sub-structures are recursively checked. Although this framework doesn’t guarantee correctness of the ID functions, it detects the vast majority of scenarios where message integrity may be inadvertently compromised by future changes and bugs.
Custom Linter For Immutable Construction
A collision-resistant message ID isn’t very helpful if business logic is free to mutate messages and models. Conceptually, messages represent binding, fixed commitments by the message creator to the message contents. A Vote represents a commitment by a Consensus Node to a proposed block, an Execution Result represents a commitment by an Execution Node to the state after executing a block.
If nodes could change their mind about what block is next, or what the result of a transaction is, that would be bad! To prevent this, if a node ever publishes two conflicting messages, they can have their stake slashed and be removed from the network. To protect node operators, the node software is designed to proactively prevent this from happening.
The main implementation of Flow node software is developed in Go, which does not natively support immutability. This means that, absent other interventions, any business logic which operates on a message or model is able to mutate it.
In order to reduce the surface area for mutation bugs and simplify the mental model for engineers and AI agents, we developed structwrite, a custom linter to enforce immutability of struct types. Types are individually opted in to mutation protection using a comment directive.
For example, the bottom line of the documentation for Header below marks the type as mutation-protected:
// Header contains all meta-data for a block, as well as a hash of the block payload.
// ...
//structwrite:immutable - mutations allowed only within the constructor
type Header struct {
// ...
}
At a high level, the linter accomplishes two distinct things:
- It enforces that instances of mutation-protected types are only created in a dedicated constructor function.
- Prevents already-constructed instances of mutation-protected types from being mutated.
The linter is implemented as a plugin to golangci-lint and runs alongside other static validations in our CI pipeline.
Boundary Type Translation
Flow nodes operate on data at various stages of validation and trust. It is important not to trust a newly received message which may be malicious. It is also important to avoid needlessly re-validating data every time it is read from a node’s local database.
In this release, we began partitioning message types and core data models based on trust/validation level. Messages originating from other nodes are deserialized into distinct untrusted message types. These untrusted message types cannot be directly used in internal business logic; instead they must be explicitly converted into the internal type using a dedicated constructor function. This consolidates validation logic at node boundaries and simplifies assumptions in node-internal business logic.
We consider two categories of message validity in Flow:
- Structural validity represents validity checks that can be performed by looking at the message in isolation. For example, if a vote message is missing a signature field, we can reject it without any additional information.
- Contextual validity represents validity checks that can be performed only by looking at the message in relation to other data. For example, a malicious node might propose two conflicting blocks during its turn, which is a protocol violation. Individually, the blocks may be valid, but taken together they would be invalid.
The changes in this release are focused on structural validity, because they can be uniformly performed at the network boundary. Contextual validity checks remain the responsibility of internal business logic.
Future Work
Hashing to compute message IDs is a small but steady cost in node operation. Today, ID computation accounts for approximately 2–3% of steady-state CPU. Message Hardening enables safe ID caching in the future through the immutable construction pattern. This release does not implement caching, but makes it simple and safe to add in the future.
The improvements in this release are necessary to safely support permissionless nodes of all types. They also specifically enable the Protocol Team’s next milestone of supporting permissionless Collection Nodes on Flow Mainnet.
These Data Integrity improvements ship with the Forte network upgrade (October 22nd, 2025). For details, see the release notes here.