


During phases of the Crescendo update, Flow experienced periods of unresponsiveness. This analysis provides insight into the causes and solutions to the network issue.
Crescendo Downtime Summary
Although the initial phase of the Crescendo update took longer than planned, minor interruptions were anticipated. However, an extended unforeseen outage occurred after planned downtime, lasting approximately 30.5 hours, during which engineering team members worked to identify the cause and solution to the network issues.
Amid the restart, it was found that messaging queues were in a self-sustained constant state of overflow. This unresponsiveness message volume needed to be reduced, and to achieve this several Flow Foundation nodes were briefly taken offline to allow the remaining nodes to coordinate with peers and catch up on processing queues. The Flow Foundation nodes came online with empty queues, and could thus rapidly process peer requests, bringing the network back to normal operation.
For an analogy, Imagine the network as a restaurant, with the nodes acting as guests. At first, patrons can easily talk to one another. But as more guests arrive, the noise increases, making it harder to hear. To compensate, everyone starts speaking louder, which only makes the noise worse until no one can hear anything at all. To fix the problem, restaurant-goers must coordinate, speaking softly to alleviate background noise and once more facilitate time-efficient communication without whispering.
Launch Lessons
Building and maintaining a high-volume, fast-paced, decentralized network while introducing major improvements pushed the networking layer beyond capacity during startup. As a result, the release, encompassing over a year of engineering efforts, encountered unforeseen issues when attempted in a single major push. In contrast, Aptos, another fast-paced network, operates with fewer validators (148 as of September 20th, 2024), showing that Flow, with 447 nodes at the time of the Crescendo launch, is pushing the boundary of decentralization and complexity for fast-paced larger-scale networks.
The self-sustaining overload state was not an issue of raw throughput or message frequency but rather, the network entering a feedback loop where overloaded nodes continue requesting missing information without being able to process the responses. This behavior mirrors complex systems reaching a Nash equilibrium, where self-sustaining states like traffic jams or noise escalation persist without clear obstacles.
Networks designed for mainstream use cases need to handle high data volumes at rapid speeds. Flow is uncovering the limits of existing technologies like libP2P in terms of scaling, latency, and resiliency.
Initial Launch
The first phase of the Crescendo upgrade to Flow involved a large-scale migration, which was anticipated to take significant time, with the potential for hiccups and challenges.
The launch was initially delayed due to bugs and an unexpectedly prolonged shutdown of partner nodes. Just after 11 am UTC Cadence 1.0 migrations were completed and data began serializing to disc, following which a migration report was published.
Unforeseen Launch Issues
After the commencement of Phase 1 of the Crescendo upgrade, an unanticipated issue occurred, rendering the network largely unresponsive for approximately 11 hours.
After the announcement early September 5 that the network had come back online, it stayed up for just over a half hour until a large number of nodes simultaneously attempted to catch up on 12 hours of blocks, which overwhelmed Flow’s networking implementation.
At the moment, it is believed that the root cause is a lack of prioritization of messages required to extend the chain versus helping the lagging nodes that can’t contribute to building on the most recent blocks while they catch up. In a nutshell, nodes that were contributing to extending the chain suddenly became overwhelmed by catch-up requests from the new nodes. This caused the extending nodes to drop a significant fraction of messages (without any prioritization) and hence miss progress-relevant updates. Further complicating issues, the nodes also started to send requests about the missed messages.
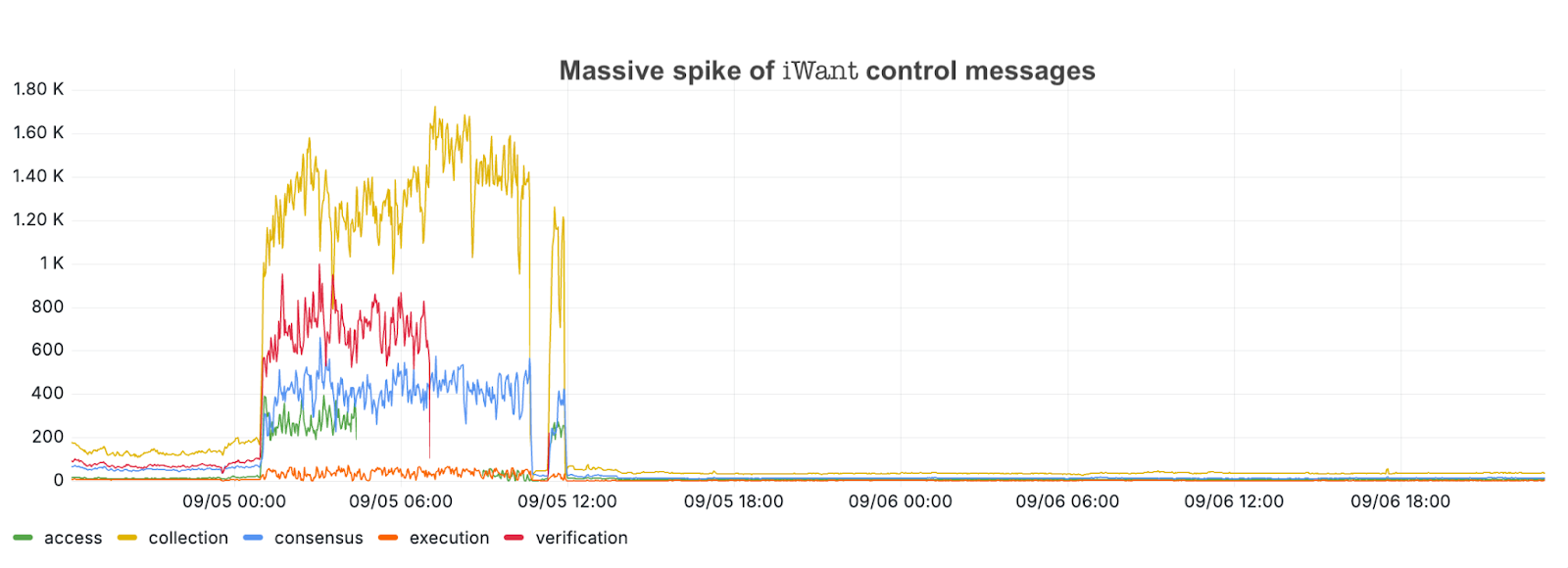
Just over an hour later, at 2:13 am UTC, the network stopped processing transactions. The investigation into the root cause of the issue continued for hours. Throughout the downtime the following observations were made:
- Some Flow Foundation nodes saw 1000s of libp2p gossip messages per second.
- Initially, the team suspected that 1 or more byzantine nodes may be spamming the system. However, the team found that the high message rates were mainly re-sent messages (presumably in response to prior requests) and control messages from libp2p, which was originally designed for slower-paced Proof-of-Work consensus where nodes essentially only exchange blocks. In contrast, the multi-node architecture of Flow has a dramatically higher message rate and a need for detailed coordination, depending on the different node types.
- As nodes could not establish reliable communication with their peers, nodes started to reduce their reliability score for their respective peers, which in addition might have made the situation worse.
In response, the team took the following actions:
- To mitigate communication spam, outbound messages and the outbound sync engine messages were throttled where instances of excessive message volume occurred.
- Adding additional logging to determine the source and contents of the spam messages.
- An investigation was made into whether the queues for lib2b in inbound and outbound messages were the same. If so, whether those queues would fill up simultaneously during a spike needed to be confirmed.
- Peer scoring, a libp2p feature used for node reputation management, was disabled.
However, despite these disabled peer-scoring elements, attempts to restart the nodes did not result in network recovery. In response, virtual machine sizes were updated and nodes were restarted. Of note, a software-only restart also did not alleviate the issues; it took a full virtual machine restart to recover the network after the Consensus Nodes were updated.
Build The Future On Flow
With Crescendo, Flow continues to push the limits of interoperability, sophistication, and onchain security. Keep track of the latest news about Flow by subscribing to the newsletter for updates.


